

VLA進化到ViLLA,智元發(fā)布首個通用具身基座大模型GO-1
http://m.sharifulalam.com 2025-03-10 10:13 來源:智元機器人
智元發(fā)布首個通用具身基座模型——智元啟元大模型(Genie Operator-1),它開創(chuàng)性地提出了Vision-Language-Latent-Action (ViLLA) 架構(gòu),該架構(gòu)由VLM(多模態(tài)大模型) + MoE(混合專家)組成,其中VLM借助海量互聯(lián)網(wǎng)圖文數(shù)據(jù)獲得通用場景感知和語言理解能力,MoE中的Latent Planner(隱式規(guī)劃器)借助大量跨本體和人類操作視頻數(shù)據(jù)獲得通用的動作理解能力,MoE中的Action Expert(動作專家)借助百萬真機數(shù)據(jù)獲得精細(xì)的動作執(zhí)行能力,三者環(huán)環(huán)相扣,實現(xiàn)了可以利用人類視頻學(xué)習(xí),完成小樣本快速泛化,降低了具身智能門檻,并成功部署到智元多款機器人本體,持續(xù)進化,將具身智能推上了一個新臺階。
研究論文:https://agibot-world.com/blog/agibot_go1.pdf
2024年底,智元推出了 AgiBot World,包含超過100萬條軌跡、涵蓋217個任務(wù)、涉及五大場景的大規(guī)模高質(zhì)量真機數(shù)據(jù)集。基于AgiBot World,智元今天正式發(fā)布智元通用具身基座大模型 Genie Operator-1(GO-1)。
01 GO-1:VLA進化到ViLLA
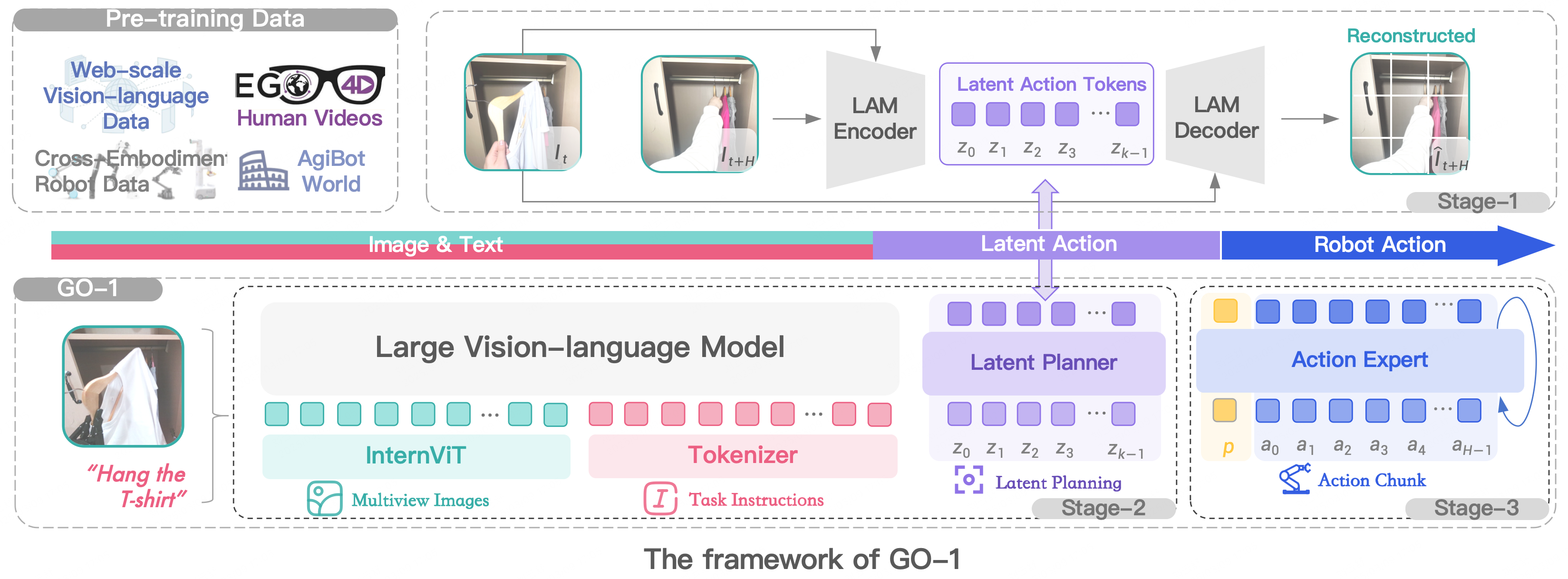
為了有效利用高質(zhì)量的AgiBot World數(shù)據(jù)集以及互聯(lián)網(wǎng)大規(guī)模異構(gòu)視頻數(shù)據(jù),增強策略的泛化能力,智元提出了 Vision-Language-Latent-Action (ViLLA) 這一創(chuàng)新性架構(gòu)。GO-1作為首個通用具身基座大模型,基于ViLLA構(gòu)建。與Vision-Language-Action (VLA) 架構(gòu)相比,ViLLA 通過預(yù)測Latent Action Tokens(隱式動作標(biāo)記),彌合圖像-文本輸入與機器人執(zhí)行動作之間的鴻溝。在真實世界的靈巧操作和長時任務(wù)方面表現(xiàn)卓越,遠遠超過了已有的開源SOTA模型。
ViLLA架構(gòu)是由VLM(多模態(tài)大模型) + MoE(混合專家)組成,其中VLM借助海量互聯(lián)網(wǎng)圖文數(shù)據(jù)獲得通用場景感知和語言理解能力,MoE中的Latent Planner(隱式規(guī)劃器)借助大量跨本體和人類操作數(shù)據(jù)獲得通用的動作理解能力,MoE中的Action Expert(動作專家)借助百萬真機數(shù)據(jù)獲得精細(xì)的動作執(zhí)行能力。在推理時,VLM、Latent Planner和Action Expert三者協(xié)同工作:VLM 采用InternVL-2B,接收多視角視覺圖片、力覺信號、語言輸入等多模態(tài)信息,進行通用的場景感知和指令理解;Latent Planner是MoE中的一組專家,基于VLM的中間層輸出預(yù)測Latent Action Tokens作為CoP(Chain of Planning,規(guī)劃鏈),進行通用的動作理解和規(guī)劃;Action Expert是MoE中的另外一組專家,基于VLM的中間層輸出以及Latent Action Tokens,生成最終的精細(xì)動作序列;
下面展開介紹下MoE里2個關(guān)鍵的組成Latent Planner和Action Expert:
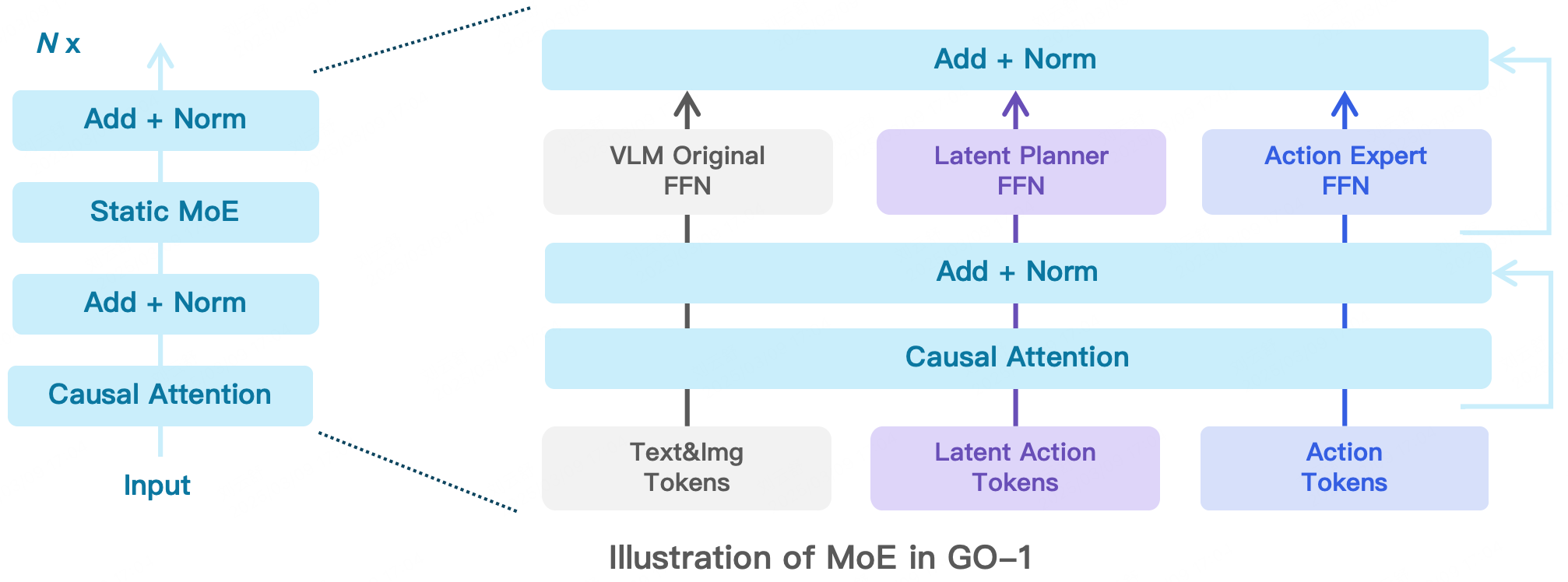
混合專家一:Latent Planner(隱式規(guī)劃器)
盡管AgiBot World 數(shù)據(jù)集已經(jīng)是全球最大的機器人真機示教數(shù)據(jù)集,但這樣高質(zhì)量帶動作標(biāo)簽的真機數(shù)據(jù)量仍然有限,遠少于互聯(lián)網(wǎng)規(guī)模的數(shù)據(jù)集。為此,我們采用Latent Actions(隱式動作)來建模當(dāng)前幀和歷史幀之間的隱式變化,然后通過Latent Planner預(yù)測這些Latent Actions,從而將異構(gòu)數(shù)據(jù)源中真實世界的動作知識轉(zhuǎn)移到通用操作任務(wù)中。
Latent Action Model(LAM,隱式動作模型)主要用于獲取當(dāng)前幀和歷史幀之間Latent Actions的Groundtruth(真值),它由編碼器和解碼器組成。其中:編碼器采用Spatial-temporal Transformer,并使用Causal Temporal Masks(時序因果掩碼)。解碼器采用Spatial Transformer,以初始幀和離散化的Latent Action Tokens作為輸入。Latent Action Tokens通過VQ-VAE的方式進行量化處理。
Latent Planner負(fù)責(zé)預(yù)測這些離散的Latent Action Tokens,它與VLM 主干網(wǎng)絡(luò)共享相同的 Transformer 結(jié)構(gòu),但使用了兩套獨立的FFN(前饋神經(jīng)網(wǎng)絡(luò))和Q/K/V/O(查詢、鍵、值、輸出)投影矩陣。Latent Planner這組專家會逐層結(jié)合 VLM 輸出的中間信息,通過Cross Entropy Loss(交叉熵?fù)p失)進行監(jiān)督訓(xùn)練。
混合專家二:Action Expert(動作專家)
為了實現(xiàn) High-frequency(高頻率)且 Dexterous(靈活)的操控,我們引入Action Expert,其采用Diffusion Model作為目標(biāo)函數(shù)來建模低層級動作的連續(xù)分布。Action Expert結(jié)構(gòu)設(shè)計上與Latent Planner類似,也是與 VLM 主干網(wǎng)絡(luò)共享相同的 Transformer 結(jié)構(gòu),但使用兩套獨立的FFN和Q/K/V/O投影矩陣,它通過Denoising Process(去噪過程)逐步回歸動作序列。Action Expert與VLM、Latent Planner分層結(jié)合,確保信息流的一致性與協(xié)同優(yōu)化。
實驗效果
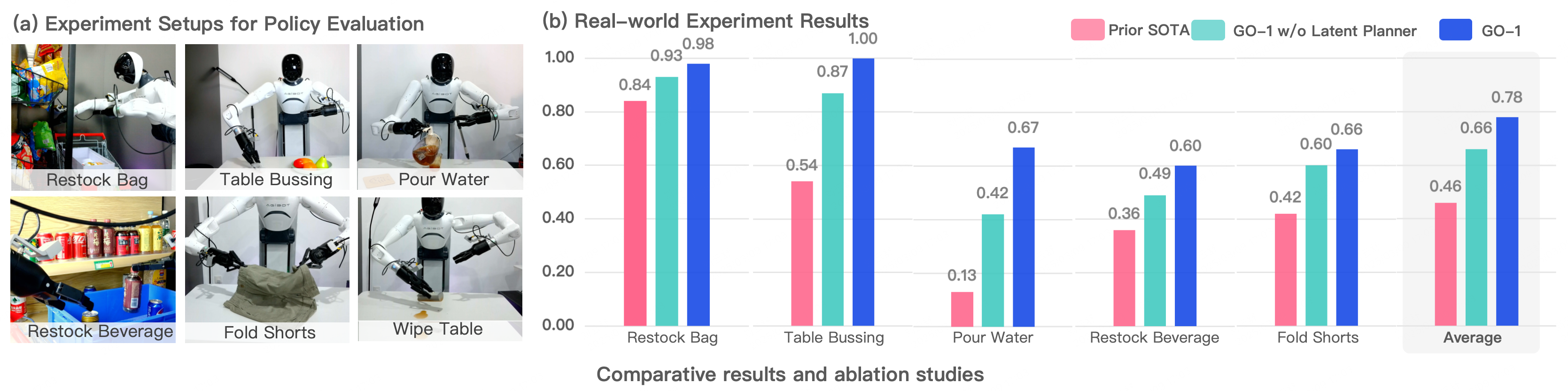
通過Vision-Language-Latent-Action (ViLLA) 創(chuàng)新性架構(gòu),我們在五種不同復(fù)雜度任務(wù)上測試 GO-1,相比已有的最優(yōu)模型,GO-1成功率大幅領(lǐng)先,平均成功率提高了32%(46%->78%)。其中 “Pour Water”(倒水)、“Table Bussing”(清理桌面) 和 “Restock Beverage”(補充飲料) 任務(wù)表現(xiàn)尤為突出。此外我們還單獨驗證了ViLLA 架構(gòu)中Latent Planner的作用,可以看到增加Latent Planner可以提升12%的成功率(66%->78%)。
02 GO-1:具身智能的全面創(chuàng)新
GO-1大模型借助人類和多種機器人數(shù)據(jù),讓機器人獲得了革命性的學(xué)習(xí)能力,可泛化應(yīng)用到各類的環(huán)境和物品中,快速適應(yīng)新任務(wù)、學(xué)習(xí)新技能。同時,它還支持部署到不同的機器人本體,高效地完成落地,并在實際的使用中持續(xù)不斷地快速進化。
這一系列的特點可以歸納為4個方面:人類視頻學(xué)習(xí):GO-1大模型可以結(jié)合互聯(lián)網(wǎng)視頻和真實人類示范進行學(xué)習(xí),增強模型對人類行為的理解,更好地為人類服務(wù)。小樣本快速泛化:GO-1大模型具有強大的泛化能力,能夠在極少數(shù)據(jù)甚至零樣本下泛化到新場景、新任務(wù),降低了具身模型的使用門檻,使得后訓(xùn)練成本非常低。一腦多形:GO-1大模型是通用機器人策略模型,能夠在不同機器人形態(tài)之間遷移,快速適配到不同本體,群體升智。持續(xù)進化:GO-1大模型搭配智元一整套數(shù)據(jù)回流系統(tǒng),可以從實際執(zhí)行遇到的問題數(shù)據(jù)中持續(xù)進化學(xué)習(xí),越用越聰明。
智元通用具身基座大模型GO-1的推出,標(biāo)志著具身智能向通用化、開放化、智能化方向快速邁進:從單一任務(wù)到多種任務(wù):機器人能夠在不同場景中執(zhí)行多種任務(wù),而不需要針對每個新任務(wù)重新訓(xùn)練。從封閉環(huán)境到開放世界:機器人不再局限于實驗室,而是可以適應(yīng)多變的真實世界環(huán)境。從預(yù)設(shè)程序到指令泛化:機器人能夠理解自然語言指令,并根據(jù)語義進行組合推理,而不再局限于預(yù)設(shè)程序。
GO-1大模型將加速具身智能的普及,機器人將從依賴特定任務(wù)的工具,向著具備通用智能的自主體發(fā)展,在商業(yè)、工業(yè)、家庭等多領(lǐng)域發(fā)揮更大的作用,通向更加通用全能的智能未來。
相關(guān)新聞
- ? 世界機器人運動員8月大比拼
- ? 出口爆發(fā),中國工業(yè)機器人邁向高端
- ? 翼菲智能沖刺港交所 為國內(nèi)領(lǐng)先的綜合性工業(yè)機器人企業(yè)
- ? 2025RoBoLeague機器人足球聯(lián)賽總決賽在北京亦莊開賽
- ? 越疆CR 30H新品發(fā)布,行業(yè)最快30kg大負(fù)載協(xié)作機器人,來了!
- ? 雙展聯(lián)動,智啟未來:慕尼黑國際光博會與慕尼黑國際機器人及自動化技術(shù)博覽會開啟行業(yè)新篇章!
- ? 華龍訊達發(fā)布“龍芯+鴻蒙”工業(yè)機器人專用控制器
- ? 工業(yè)級機器人進入量產(chǎn)前夜,大摩預(yù)計2028中國機器人市場規(guī)模超千億美元
- ? 海康機器人第三代工業(yè)相機CT系列震撼發(fā)布!
- ? 智元主辦的全球具身智能挑戰(zhàn)賽正式開啟!
編輯精選
- ? PLC市場穩(wěn)定回暖,國產(chǎn)化進程加速推進
- ? 鴻道操作系統(tǒng)在京首發(fā) 突破“大小腦”核心技術(shù)開啟自主可控具身智能新紀(jì)元
- ? 2025年施耐德電氣創(chuàng)新峰會盛大開幕
- ? ABB 加速器中國周為創(chuàng)新加速
- ? 羅克韋爾自動化發(fā)布第十版《智能制造現(xiàn)狀報告》
- ? 西門子舉辦“Realize LIVE”大會
- ? 埃夫特牽頭成立 “高速高精技術(shù)創(chuàng)新聯(lián)合體”,助力長三角一體化發(fā)展
- ? 匯川技術(shù)分拆聯(lián)合動力上市,關(guān)聯(lián)交易增收引關(guān)注
- ? 東土科技參與國家重點研發(fā)計劃 ,共同研發(fā)工業(yè)智控創(chuàng)新技術(shù)
- ? 2025華南國際工業(yè)博覽會圓滿閉幕
工控原創(chuàng)
- ? 一文get六月工控自動化大事
- ? ABB加速器中國周:當(dāng)AI邂逅硬核工業(yè),一場自下而上的智造革命
- ? 點擊了解5月工控圈那些事兒
- ? 分拆上市還是出售?ABB機器人業(yè)務(wù)將何去何從
- ? 打造標(biāo)桿案例及生態(tài)圈,ABB全力推動Ethernet-APL應(yīng)用加速
- ? 你關(guān)心的四月份工控大事全在這里
- ? 匯川技術(shù)2024年財報解析:多元化布局彰顯增長韌性
- ? 關(guān)稅政策讓美國工業(yè)自動化復(fù)蘇之路面臨不確定性
- ? ADI系統(tǒng)級創(chuàng)新方案深度賦能工業(yè)智能化與能源安全
- ? 32篇新聞,帶你回顧3月工控圈熱點


